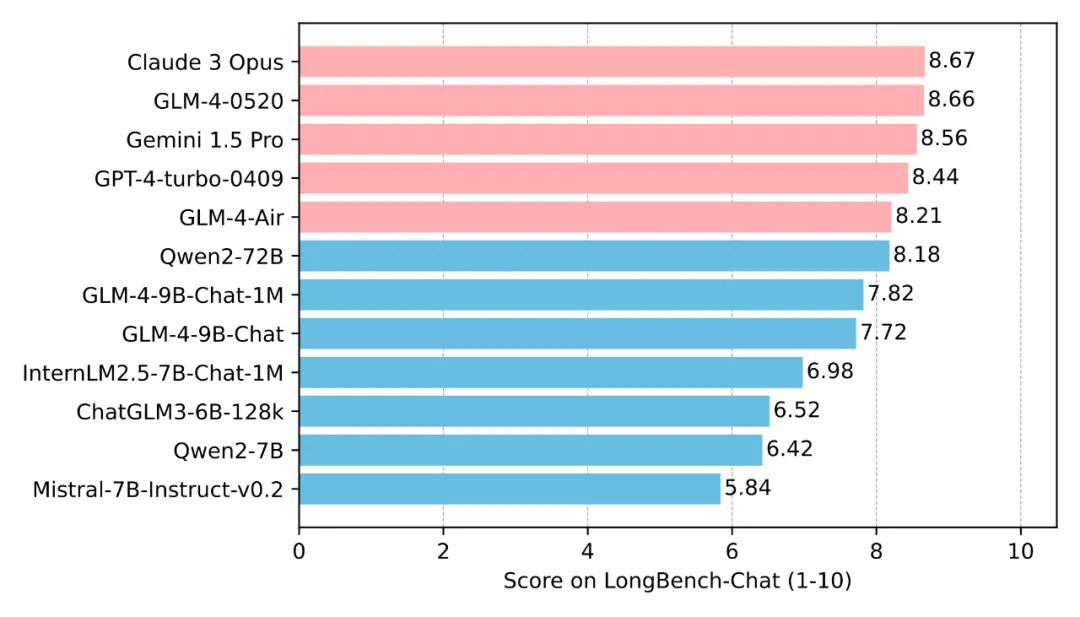
如何将 LLM 的上下文扩展至百万级?
如何将 LLM 的上下文扩展至百万级?在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k。然而,时至今日,1M的上下文长度已经成为衡量模型技术先进性的重要标志之一。
来自主题: AI技术研报
7160 点击 2024-07-19 10:14
 搜索
搜索
在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k。然而,时至今日,1M的上下文长度已经成为衡量模型技术先进性的重要标志之一。

具身智能是过去一年中和 LLM 一样受到市场高度关注的领域,通用机器人领域什么时候会出现「iPhone 时刻」?这是所有人都关注的问题。拾象团队在过去一年中也深度追踪通用机器人和机器人 foundation model 的进展。本篇文章是我们对机器人领域研究的开源。

把因果链展示给 LLM,它就能学会公理。
LLM 很强大,但也存在一些明显缺点,比如幻觉问题、可解释性差、抓不住问题重点、隐私和安全问题等。检索增强式生成(RAG)可大幅提升 LLM 的生成质量和结果有用性。
人会有幻觉,大型语言模型也会有幻觉。近日,OpenAI 安全系统团队负责人 Lilian Weng 更新了博客,介绍了近年来在理解、检测和克服 LLM 幻觉方面的诸多研究成果。

只要仍使用英语训练 LLM 模型,美国就还有优势。

谷歌作为全球领先的科技公司,在 AI 领域拥有深厚的积累和卓越的创新能力,在谷歌眼里,生成式 AI 带来了哪些机会?Google AI 是如何在谷歌产品中落地的?Google Cloud 提供了一系列工具和平台,如何帮助开发者构建和部署自己的专属 LLM 和 Agent?负责任的 AI 为企业带来哪些价值?

上下文学习 (in-context learning, 简写为 ICL) 已经在很多 LLM 有关的应用中展现了强大的能力,但是对其理论的分析仍然比较有限。人们依然试图理解为什么基于 Transformer 架构的 LLM 可以展现出 ICL 的能力。

很多人认为智能体(agent)是生成式人工智能的未来趋势。但对于智能体应该如何发展大家却看法不一。基于简单的链式流程的智能体还不够灵活或强大,没有真正利用好 LLM 范式,而完全自主的智能体往往又会失效,没法用。在二者之间找到平衡的“金凤花”智能体正赢得青睐。

在GPT-4发布后14.5个月里,LLM领域似乎已经没什么进步了?近日,马库斯的一句话引发了全网论战。大模型烧钱却不赚钱,搞AI的公司表示:难办!